
起首:赛博禅心
就在刚刚,好意思国的另一家 AI 巨头 Anthropic 的 CEO - Dario Amodei 发表了一篇长达万字的深度分析叙述。叙述中枢不雅点:DeepSeek 的糟蹋,愈加印证了好意思国对华芯片出口管制政策的必要性和波折性。

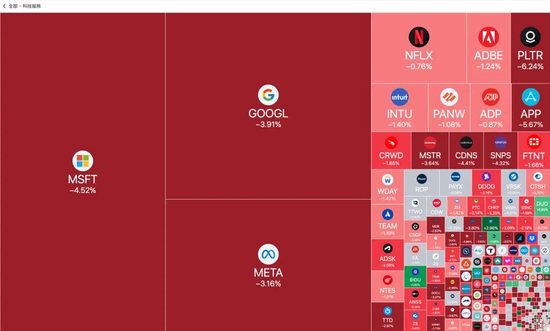
先补充下前提,这几天,DeepSeek 刷屏、刷屏、再刷屏。
并在新春之际,给西洋股市带来了一抹中国红(暴跌)
赛博禅心在此前也通过多个纬度,对此进行了一系列报谈:
DeepSeek 彻底指南:这到底是若何的存在?
DeepSeek-V3 是奈何磨练的|深度拆解
DeepSeek-R1 是奈何磨练的|深度拆解
DeepSeek 再度开源:用 Janus-Pro 撕开算力铁幕
顺谈着...昨天凌晨,Qwen 也发了大货:
金色外传大机灵,公众号:赛博禅心春晚硬科技清点:我很少用‘闲逸’描画一场盛开
咱们回衰败来望望 Dario Amodei 这篇叙述,里面起初降服了 DeepSeek 的时刻糟蹋:其最新模子在特定基准测试中已靠拢好意思国顶尖水平,模子磨练效率提高显耀,并尝试将中国 AI 跨越纳入各人时刻演进坐标系进行定位,从三个维度:
算力领域定律: 指出中国超大领域算力基建的不时干预,正在重塑各人 AI 研发的地缘花式。国度级数字基础智商的计谋布局,为中国企业糟蹋“算力界限”提供了底层复旧。
效率跃迁弧线: 强调各人 AI 行业正资历磨炼就本指数级下降的时刻更动。DeepSeek 的成本法规糟蹋,实践上是把抓时刻演进窗口期的计谋已矣。
范式革新动能: 珍贵分析中国团队在强化学习等新兴磨练范式中的创新实践,揭示后发者通过时刻阶梯创新竣事弯谈超车的可能性。
基于此,Dario Amodei 的论断颇具启示性:DeepSeek 的糟蹋绝非孤独时势,而是中国科技创新体系系统性进化的居品。尽管叙述刻意淡化“颠覆性创新”的叙事,但字里行间对中国 AI 发展势能的警惕已栩栩欲活。
在政策维度,叙述剑指芯片出口管制的计谋逆境。Dario Amodei 坦承,DeepSeek 的糟蹋正在倒逼好意思国重新评估时刻封闭政策的有用性。这种政策层面的四百四病,恰印证了中国 AI 解围对各人时刻步骤的重构效应。其中枢论断直指要害——算力霸权已成为 AI 竞赛的赢输手,而中国在自主可控产业链涵养方面的进展,正在动摇传统时刻封闭的逻辑基础。
叙述同期指出,在国度安全与时刻发展间,需要寻求动态均衡,这亦然当下各人的时间命题:那时刻演进速率,已高出政策颐养速率,如安在绽放与风控中确立新范式,已成为关节中的关节。
需要说一下,Dario Amodei 是前 OpenAI 的磋议员,自后离开 OpenAI 后诞生其径直竞争敌手 Anthropic。这篇叙述在保持学术矜持的表象下,强硬承认中国 AI 崛起的事实,也预示着创新花式正在发生范式退换——从单一中心的时刻辐照,向多极共生的生态演进。
著作发布在 Dario Amodei 的个东谈主博客:https://darioamodei.com/on-deepseek-and-export-controls
我把它也翻译成了汉文,如下:
对于 DeepSeek 与出口管制
几周前,我曾撰文命令好意思国应加强对华芯片出口管制。尔后不久,中国东谈主工智能公司 DeepSeek 便奏效地——至少在某些方面——以更低的成本,竣事了与好意思国顶尖东谈主工智能模子左右的性能水平。
在此,我暂且不筹商 DeepSeek 是否对 Anthropic 等好意思国东谈主工智能企业组成阻止(尽管我以为许多对于 DeepSeek 阻止好意思国东谈主工智能指引地位的说法被严重夸大了)。
我更关怀的是,DeepSeek 的已矣发布是否削弱了芯片出口管制政策的合感性。我的倡导是申辩的。事实上,我以为 DeepSeek 的进展反而令出口管制政策显得比一周前更具存介怀念念上的枢纽性。
出口管制工作于一个至关枢纽的磋议:确保民主国度在东谈主工智能发展中保持起初地位。需要明确的是,出口管制并非藏匿好意思中竞争的技巧。最终,要是好意思国和其他民主国度的 AI 公司想要胜出,就必须拓荒出比中国更超卓的模子。但是,在力所能及的情况下,咱们不应将时刻上风拱手让给中国。
东谈主工智能发展的三大动态
在进展我的政策主张之前,我将先先容认识东谈主工智能系统至关枢纽的三个基本动态:
领域定律 (Scaling laws)。 东谈主工智能的一个特质——我和我的和洽首创东谈主在 OpenAI 使命时就率先记载了这一特质——即在其他条目调换的情况下,扩大东谈主工智能系统的磨练领域,能够全面且平滑地提高其在多样默契任务上的浮现。
举例,一个耗资 100 万好意思元的模子可能科罚 20%的枢纽编程任务,一个耗资 1000 万好意思元的模子可能科罚 40%,一个耗资 1 亿好意思元的模子可能科罚 60%,依此类推。这些各别在实践中时常具有巨大的影响——十倍的性能提高可能相等于本科生和博士生技能水平之间的差距——因此,各公司王人在放纵投资于磨练这些模子。
弧线偏移 (Shifting the curve)。 东谈主工智能领域不断自大多样万里长征的创新理念,旨在提高效率或效力。这些创新可能体现在模子架构的纠正上(举例对面前通盘模子王人经受的 Transformer 基础架构进行微调),也可能只是是更高效地在底层硬件上运转模子的方法。
新一代硬件的出现也具有调换的效果。这些创新频频会使成本弧线发生偏移:要是某项创新带来了 2 倍的“算力倍增效应”(CM),那么正本需要破耗 1000 万好意思元材干完成 40%编程任务,现在只需 500 万好意思元即可竣事;正本需要 1 亿好意思元材干完成 60%的任务,现在只需 5000 万好意思元,依此类推。每一家前沿东谈主工智能公司王人会按时发现许多这么的算力倍增效应:微型创新(约 1.2 倍)时有发生,中型创新(约 2 倍)也偶有出现,而大型创新(约 10 倍)则较为荒废。
由于领有更智能系统的价值极高,这种弧线偏移频频会导致公司在模子磨练上干预更多而非更少的资金:成本效率的提高最终彻底用于磨练更智能的模子,独一制约身分仅为公司的财务资源。东谈主们当可是然地倾向于“先贵后贱”的念念维模式——仿佛东谈主工智能是一种质料恒定的单一事物,当它变得更便宜时,咱们就会用更少的芯片来磨练它。但关节在于领域弧线:当弧线偏一霎,咱们只是更快地沿着弧线前进,因为弧线终点的价值实在太高了。
2020 年,我的团队发表了一篇论文,指出算法跨越带来的弧线偏移约为每年 1.68 倍。尔后,这个速率可能已显耀加速;而且这还莫得考虑效率和硬件的跨越。我臆想今天的数字可能约为每年 4 倍。此处还有另一项臆想。磨练弧线的偏移也会带动推理弧线的偏移,因此,多年来,在模子质料保持不变的情况下,价钱大幅下降的情况一直王人在发生。举例,Claude 3.5 Sonnet 的 API 价钱比原版 GPT-4 低约 10 倍,但其发布时辰比 GPT-4 晚了 15 个月,且在险些通盘基准测试中王人优于 GPT-4。
范式退换 (Shifting the paradigm)。 有时,被领域化的底层事物会发生隐微变化,或者在磨练流程中会加入一种新的领域化形状。在 2020 年至 2023 年期间,主要的领域化对象是预磨练模子:即使用越来越多的互联网文本进行磨练,并在其基础上进行少许其他磨练的模子。
2024 年,使用强化学习(RL)磨练模子生成念念维链的想法已成为新的领域化重心。Anthropic、DeepSeek 和许多其他公司(省略最引东谈主注视的是 OpenAI,他们在 9 月份发布了 o1-preview 模子)王人发现,这种磨练形状极地面提高了模子在某些特定、可客不雅掂量的任务上的性能,举例数学、编程竞赛以及与这些任务不异的推理。这种新范式包括起初使用普通的预磨练模子,然后在第二阶段使用强化学习来添加推理技能。
枢纽的是,由于这种类型的强化学习是全新的,咱们仍处于领域弧线的早期阶段:通盘参与者在第二阶段(强化学习阶段)的干预王人很少。干预 100 万好意思元而不是 10 万好意思元就足以取得巨大的收益。各公司面前王人在迅速死力将第二阶段的干预领域扩大到数亿好意思元以致数十亿好意思元,但至关枢纽的是要认识,咱们正处在一个私有的“交叉点”,即存在一种刚劲的新范式,它正处于领域弧线的早期阶段,因此不错迅速取得要紧进展。
DeepSeek 的模子
上述三个动态不错匡助咱们认识 DeepSeek 近期发布的模子。大要一个月前,DeepSeek 发布了一个名为“DeepSeek-V3”的模子,这是一个地谈的预磨练模子——即上述第三点中容貌的第一阶段。上周,他们又发布了“R1”,在 V3 的基础上加多了第二阶段。从外部无法彻底了解这些模子的一谈信息,但以下是我对这两次发布的最好认识。
DeepSeek-V3 实践上是真实的创新方位,一个月前就应该引起东谈主们的扎眼(咱们虽然扎眼到了)。动作一款预磨练模子,它在某些枢纽任务上的浮现似乎已接近好意思国起初进的模子水平,但磨炼就本却大大缩小(不外,咱们发现,衰败是 Claude 3.5 Sonnet 在某些其他关节任务上,举例实践编程方面,仍然光显更胜一筹)。DeepSeek 团队通过一些真实令东谈主印象真切的创新竣事了这一丝,这些创新主要聚拢在工程效率方面。衰败是在名为“键值缓存 (Key-Value cache)”的某一方面管理以及鼓励“夹杂众人 (mixture of experts)”方法更进一步的诳骗上,取得了创新性的纠正。
可是,有必要进行更深入的分析:
DeepSeek 并未“以 600 万好意思元的成本竣事了好意思国东谈主工智能公司数十亿好意思元干预的效果”。我只可代表 Anthropic 发言,Claude 3.5 Sonnet 是一款中等领域的模子,磨炼就本为数千万好意思元(我不会给出真实数字)。此外,3.5 Sonnet 的磨练形状与任何领域更大或成本更高的模子无关(与某些传言违反)。Sonnet 的磨练是在 9-12 个月前进行的,而 DeepSeek 的模子是在 11 月/12 月磨练的,但 Sonnet 在许多里面和外部评估中仍然显耀起初。因此,我以为一个公谈的说法是:“DeepSeek 坐蓐出了一款性能接近好意思国 7-10 个月前模子的模子,成本大幅缩小(但远未达到东谈主们所说的比例)”。
要是成本弧线的历史下降趋势约为每年 4 倍,这意味着在浮浅的生意进度中——在 2023 年和 2024 年发生的历史成本下降等浮浅趋势下——咱们预测现在会出现一款比 3.5 Sonnet/GPT-4o 便宜 3-4 倍的模子。
由于 DeepSeek-V3 的性能不如那些好意思国前沿模子——假定在领域弧线上落伍约 2 倍,我以为这对于 DeepSeek-V3 来说一经相等清翠了——这意味着,要是 DeepSeek-V3 的磨炼就本忘形国一年前拓荒的现存模子低约 8 倍,那将是彻底浮浅、彻底顺应“趋势”的。我不会给出具体数字,但从前一丝不错了了地看出,即使你彻底信托 DeepSeek 声称的磨炼就本,他们的浮现充其量也只是顺应趋势,以致可能还够不上。举例,这远不如最初的 GPT-4 到 Claude 3.5 Sonnet 的推理价钱各别(10 倍),而 3.5 Sonnet 是一款比 GPT-4 更出色的模子。
一言以蔽之,DeepSeek-V3 并非一项私有的糟蹋,也并非从根柢上篡改了大型言语模子 (LLM) 的经济性;它只是不时成本缩小弧线上一个预期的点。此次的不同之处在于,第一个展示预期成本缩小的公司是中国公司。这在畴前从未发生过,何况具有地缘政事意念念。可是,好意思国公司很快也会效仿——而且他们不融会过复制 DeepSeek 来作念到这一丝,而是因为他们也在竣事频频的成本缩小趋势。
DeepSeek 和好意思国东谈主工智能公司王人比以往领有更多的资金和更多的芯片来磨练其明星模子。极端的芯片用于研发赈济模子背后的理念,有时也用于磨练尚未准备就绪(或需要屡次尝试材干奏效)的更大模子。有报谈称——咱们无法详情其真实性——DeepSeek 实践上领有 50,000 块 Hopper 架构的芯片,我猜这与好意思国主要东谈主工智能公司领有的芯片数目在 2-3 倍的差距内(举例,比 xAI 的 “Colossus” 集群少 2-3 倍)。这 50,000 块 Hopper 芯片的成本约为 10 亿好意思元。因此,DeepSeek 动作一家公司的总开销(与磨练单个模子的开销不同)与好意思国东谈主工智能实验室的开销并莫得一丈差九尺。
值得扎眼的是,“领域弧线”分析有些过于简化,因为模子在某种程度上是存在各别的,何况各有优过失;领域弧线数字是一个豪放的平均值,忽略了许多细节。我只可谈谈 Anthropic 的模子,但正如我上头浮现的那样,Claude 在编程和与东谈主进行邃密遐想的互动立场方面相等出色(好多东谈主用它来寻求个东谈主提倡或赈济)。在这些以及一些极端的任务上,DeepSeek 彻底无法与之同等看待。这些身分在领域数字中并未体现出来。
上周发布的 R1 模子激励了公众的平凡关怀(包括英伟达股价下落约 17%),但从创新或工程角度来看,它远不如 V3 风趣。R1 模子加多了第二阶段的磨练——强化学习,在前一节的第 3 点中对此进行了容貌——何况基本上复制了 OpenAI 在 o1 模子中所作念的使命(他们似乎处于不异的领域,已矣也不异)。可是,由于咱们正处于领域弧线的早期阶段,只须它们从刚劲的预磨练模子起步,多家公司就有可能坐蓐出这种类型的模子。在 V3 的基础上坐蓐 R1 模子的成本可能相等便宜。因此,咱们正处于一个风趣的“交叉点”,暂时会出现多家公司王人能坐蓐出优秀的推理模子的情况。但跟着通盘公司在这种模子的领域弧线上进一步前进,这种情况将迅速隐藏。
出口管制
以上通盘内容王人只是我主要关怀话题——对华芯片出口管制——的铺垫。凭证上述事实,我对现时场所的倡导如下:
即使弧线周期性地发生偏移,磨练特定智能水平模子的成本迅速下降,但各公司在磨练刚劲东谈主工智能模子上的开销却不时加多。这只是是因为磨练更智能模子的经济价值实在太大了,以至于任何成本上的省俭险些王人立即被对消——它们被重新干预到制造更智能的模子中,破耗的仍然是最初谋划开销的巨额资金。DeepSeek 拓荒的效率创新,要是好意思国实验室尚未发现,也将很快被好意思国和中国实验室诳骗于磨练数十亿好意思元的模子。这些模子将比他们之前谋划磨练的数十亿好意思元模子性能更优——但他们仍然会破耗数十亿好意思元。这个数字将络续飞腾,直到咱们达到东谈主工智能在险些通盘事情上王人比险些通盘东谈主类更智能的程度。
制造出在险些通盘事情上,王人比险些通盘东谈主类更智能的东谈主工智能,将需要数百万块芯片、数百亿好意思元(至少),何况最有可能在 2026-2027 年竣事。DeepSeek 的已矣发布并莫得篡改这一丝,因为它们大致顺应一直被纳入这些诡计的预期成本缩小弧线。
这意味着在 2026-2027 年,咱们可能会最终进入两个毫不调换的寰球之一。在好意思国,多家公司降服会领有所需的数百万块芯片(以数百亿好意思元的成本)。问题是中国事否也能取得数百万块芯片?
要是中国能够作念到,咱们将活命在一个南北极寰球中,好意思国和中国王人将领有刚劲的东谈主工智能模子,这将导致科学和时刻的迅速发展——我称之为“数据中心里的天才之国”。南北极寰球不一定会无穷期地保持均衡。即使好意思国和中国在东谈主工智能系统方面势均力敌,中国似乎也更有可能将更多的材干、成本和关怀力干预到该时刻的军事诳骗中。勾通其弘大的工业基础和军事计谋上风,这可能有助于中国在各人舞台上取得主管地位,不仅在东谈主工智能领域,而且在通盘领域。
要是中国无法取得数百万块芯片,咱们将(至少暂时)活命在一个单极寰球中,唯有好意思国及其盟友领有这些模子。单极寰球是否会经久尚不了了,但至少存在一种可能性,即由于东谈主工智能系统最终不错匡助制造更智能的东谈主工智能系统,暂时的起初上风可能会转换为经久的上风。因此,在这个寰球中,好意思国及其盟友可能会在各人舞台上取得主管且经久的起初地位。
有用扩充的出口管制是独一能够拦阻中国取得数百万块芯片的技巧,因此亦然咱们最终会进入单极寰球照旧南北极寰球的最枢纽决定身分。
DeepSeek 的出色浮现并不虞味着出口管制失败。正如我上头所述,DeepSeek 领有相等数目的芯片,因此他们能够拓荒并磨练出一个刚劲的模子并不令东谈主不测。他们的资源料理程度并不忘形国东谈主工智能公司高若干,出口管制也不是导致他们“创新”的主要身分。他们只短长常有才华的工程师,并标明中国事好意思国的一个刚劲竞争敌手。
DeepSeek 也不可证明中国总能通过私运取得所需的芯片,或者证明管制方法老是存在裂缝。我不以为出口管制的宗旨也曾是拦阻中国取得数万块芯片。10 亿好意思元的经济活动不错被掩盖,但 1000 亿好意思元以致 100 亿好意思元的经济活动却很难遮蔽。数百万块芯片在物理上也可能难以私运。
注视一下面前报谈的 DeepSeek 领有的芯片也具有启发意念念。凭证 SemiAnalysis 的说法,这是一个由 H100、H800 和 H20 组成的夹杂体,算计 5 万块。H100 自觉布以来就受到出口管制禁令的已矣,因此要是 DeepSeek 领有任何 H100,那一定是私运来的(请扎眼,英伟达已声明 DeepSeek 的进展“彻底顺应出口管制规则”)。H800 在 2022 年最初的出口管制方法下是允许的,但在 2023 年 10 月管制方法更新时被回绝,因此这些芯片可能是在禁令之前发货的。H20 的磨练效率较低,采样效率较高——何况仍然是允许出口的,尽管我以为应该回绝出口。
一言以蔽之,DeepSeek 东谈主工智能芯片舰队的很大一部分似乎是由以下芯片组成:尚未被回绝的芯片(但应该被回绝);在被回绝之前发货的芯片;以及一些相等可能私运来的芯片。这标明出口管制实践上正在浮现作用并不断颐养:裂缝正在被堵塞;不然,他们很可能领有一谈由顶级的 H100 组成的芯片舰队。要是咱们能够弥散快地堵塞裂缝,咱们省略能够拦阻中国取得数百万块芯片,从而加多好意思国起初的单极寰球出现的可能性。
考虑到我对出口管制和好意思国国度安全的关怀,我想明确一丝。我不以为 DeepSeek 自己是敌手,重心也不是挑升针对他们。在他们选定的采访中,他们看起来像是机灵的、充满敬爱心的磋议东谈主员,只是想创造有用的时刻。
要是中国能够在东谈主工智能领域与好意思国匹敌,这个他们会是令东谈主心焦的。出口管制是咱们拦阻这种情况发生的最有劲用具之一,以为时刻变得更刚劲、性价比更高就应该减弱出口管制,这种想法根柢毫有时念念。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
株连裁剪:王长生